1. Learning Slowly
Over the past six weeks on Coursera, I’ve finished Google’s Course 5 Regression Analysis and am now halfway through Course 6 Machine Learning. Regression Analysis took longer than I expected, yet Machine Learning feels more basic than I initially anticipated. I’ve also decided to temporarily suspend my study of IBM’s certificate, as Google’s advanced certificate overlaps with it and covers slightly more ground.
I’ve been learning at a slower pace recently for several reasons.
I took an eleven-day vacation to Australia, followed by an additional four to five days of rest. Shortly after returning, I moved from one room to another (south-facing) at home. New furniture was bought, and a new built-in wardrobe was installed, so the whole process took a while. For all the effort, the room is super tidy and cozy now. Both Australia and my new room provide me with plenty of sunshine.
More importantly, I prefer depth over speed in my studies. That mindset inevitably slows things down. I tend to linger on topics that genuinely interest me, sometimes longer than planned.
Occasionally, a single question pulls me into a long chain of thinking. I might explore it through extended conversations, revisiting assumptions, clarifying definitions, and trying to reconcile different explanations. These detours are not always efficient, but they are often where my understanding changes most. One such detour came from learning about regularization in logistic regression. The following section is a light reflection on how my understanding evolved.
2. A Light Discussion on Logistic Regression Regularization
2.1 My First Cognition Gap – The Default Is penalty = ‘l2’
The assumptions I initially held were that statistical models always faithfully reflect mathematical definitions and fairly apply formulas unless otherwise stated. In that sense, for logistic regression, I thought the penalty was supposed to be set to none (no regularization at all) for a pure model. However, I learned incidentally through lab code that the default setting for LogisticRegression() in scikit-learn is l2, which corresponds to Ridge regularization. The lab doesn’t cover much on this topic, so I did my own research.
Unlike linear regression, where regularization isn’t set as default, logistic regression is solved by iterative optimization of the log-loss function. During this process, it may encounter the issue of separable data, where the best solution corresponds to infinite coefficients.
Data are linearly separable if there exists a vector β and an intercept β₀ such that
In other words, a single linear boundary can perfectly separate the two classes.
An extreme one-feature example is when, for every churned user , whereas for all retained users . This means that and.
We know that the logistic model takes the form .
When , we want , which drives .
When , we want , which requires , and therefore .
Another way of thinking about this situation is to focus on the optimization process itself. When the data are separable, once the coefficients are already near the asymptotic regions of the sigmoid, a large change in the betas only marginally improves the loss. This behavior can be seen from the shape of the sigmoid function , as well as from , which contributes to the loss when , and which contributes when . The latter two terms form the log-loss.
Figures: sigmoid function
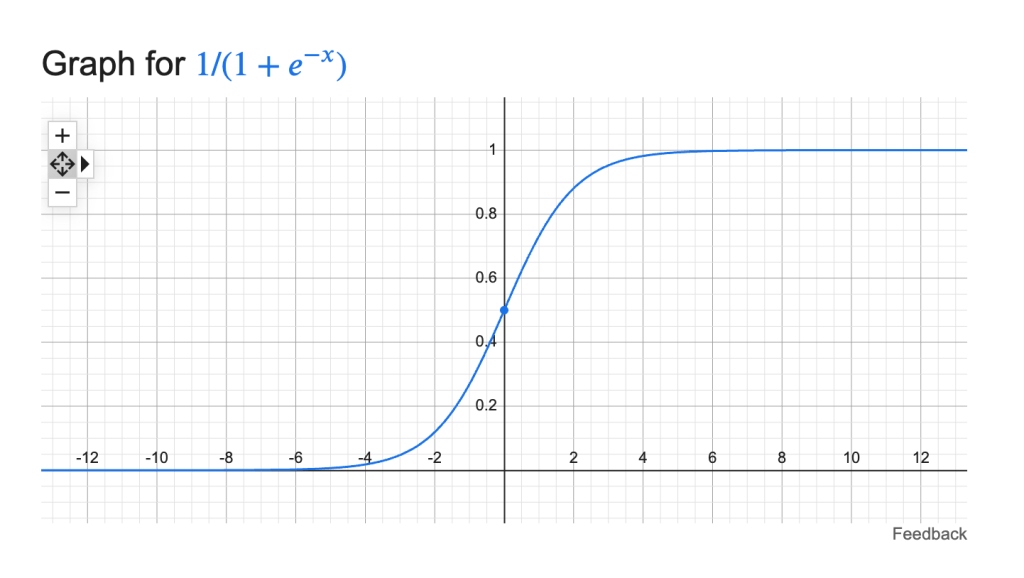
loss contribution when
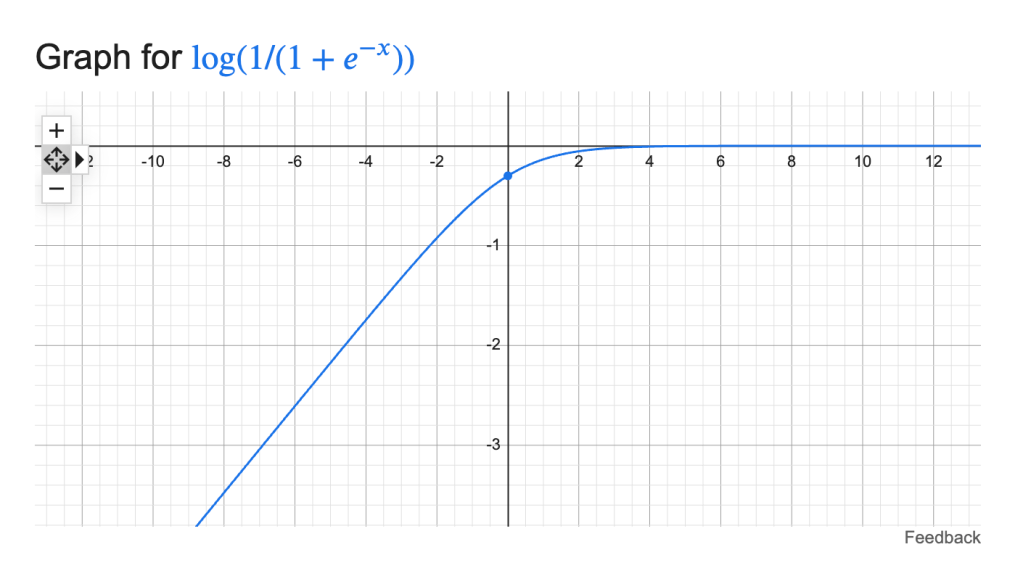
loss contribution when
We want to keep the betas from inflating and exploding while pushing for a better result (lower loss) during the optimization process.
Introducing a penalty to the model is like preinstalling seatbelts in a car. Large beta coefficients get penalized before they explode in the presence of separable or nearly separable data.
2.2 My Second Cognition Gap – Does the Default Penalty Parameter Make Sense?
Understanding why regularization exists naturally led me to a second question: does the default penalty parameter itself make sense?
It is always a good time to do some boring math.
For the logistic model, for each observation ,
where
The likelihood function over the dataset is
for binary responses .
Taking the negative log leads to the loss for a single observation,
The loss over the entire dataset, which scikit-learn uses in its mean form, is
When adding L2 regularization, the objective becomes the log-loss plus a penalty term:
where is the inverse regularization strength. In scikit-learn, the default value of is 1.
While I was initially picking up this concept, the formula ChatGPT originally provided to me missed the factor in the penalty term, which made the penalty appear excessively large. As a result, the penalty and the original loss looked completely out of proportion, and the regularization term seemed arbitrary and dominating. This confused me for quite some time. I spent hours discussing this with GPT, trying to make sense of the formula, until we eventually realized that the original expression was incorrect! (I just wanted to scream at that point — and I probably did.)
After correcting the formula by including the proper scaling, the default parameter choice started to make sense. It is reasonable and tolerant enough not to hinder overall model performance on generally good data. By “good data,” I mean data with no (near) separation, no extreme multicollinearity, sufficient sample size relative to the number of features, and coefficients that are stable across resamples.
When the data are good, logistic regression with Ridge and without Ridge produces almost identical results. The regularization term quietly disappears. Regularization mainly matters when the unregularized solution is unstable. In that sense, it really behaves like a seatbelt: always present, but only noticeable when something goes wrong. This behavior differs from Ridge in linear regression, where coefficient shrinkage is present even when the data are well behaved.
I also learned that the parameter often requires tuning in special cases, and this tuning is typically performed on a logarithmic scale (for example, ).
Finally, it is worth noting that, in practice, we almost always apply StandardScaler() before fitting the model. Since the scale of the coefficients directly affects the penalty, unscaled features can lead to coefficients being penalized unevenly. For example, without standardization, features with smaller scales may be penalized more heavily because they require larger coefficients.
3. A Small K-means Color Quantization Experiment
Not all learning moments need to be heavy. As another part of my recent study, I experimented with k-means clustering through a simple color quantization project, which I found quite interesting. In this exercise, we ignore the spatial position of each pixel in the image and group pixels into representative colors based on their RGB values. Each pixel is then replaced by its cluster’s representative color to approximate the original image.
Below are my current profile picture (taken in Australia), the centroid colors learned by k-means (ordered by brightness) with , and the corresponding quantized image (yes, it comprises only 9 colors).
Figures: Centroid colors

Original image and quantized image


For now, this is where my understanding stands.